Table of Contents
- Gli Schemi - Generalità
- Schema di default
- Aggiungere nuovi schemi
- Cos'è un Q2
- La codifica degli schemi
- Gli schemi fissi distribuiti dallo standard
- Creare nuovi schemi nell'ambiente cliente
- Gestire uno schema "S/ - Da script SCP_QRY"
- Gestire uno schema "Q/ - Da pgm B£IQ2_xx"
- Gestire uno schema "T/ - Da script SCP_NAV"
- Forme obsolete di definizione degli schemi
- Forme deprecate di definizione degli schemi
- Sospendere/Ripristinare istanze e/o fonti di schema
- Modificare il setup dello schema
- Documenti operativi
Gli Schemi - Generalità
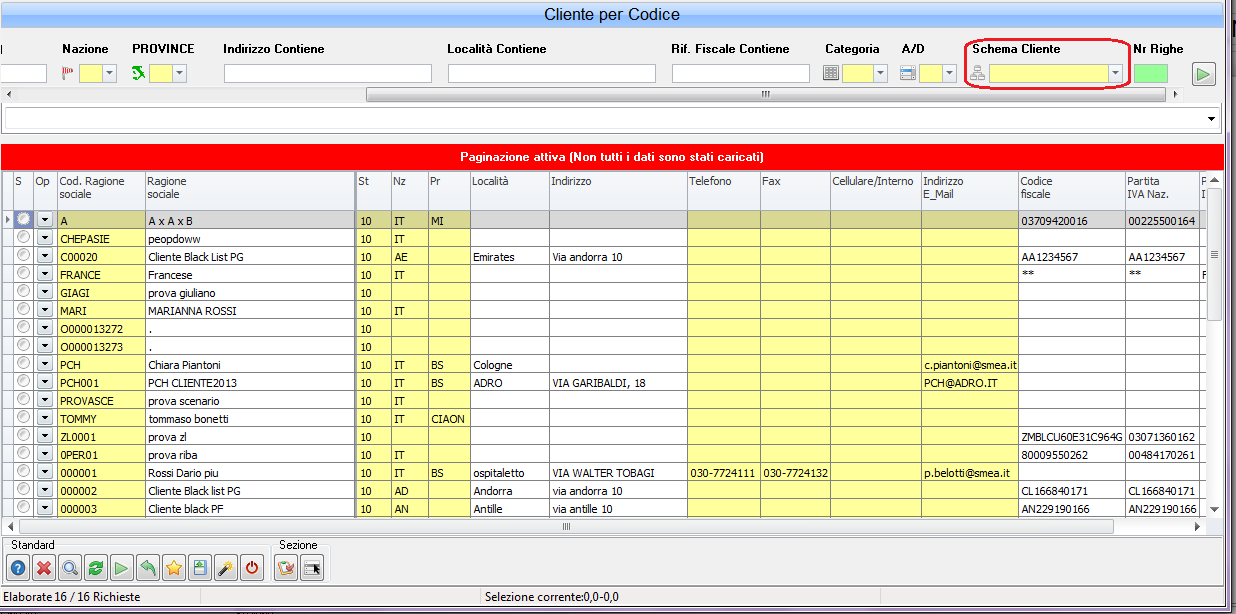
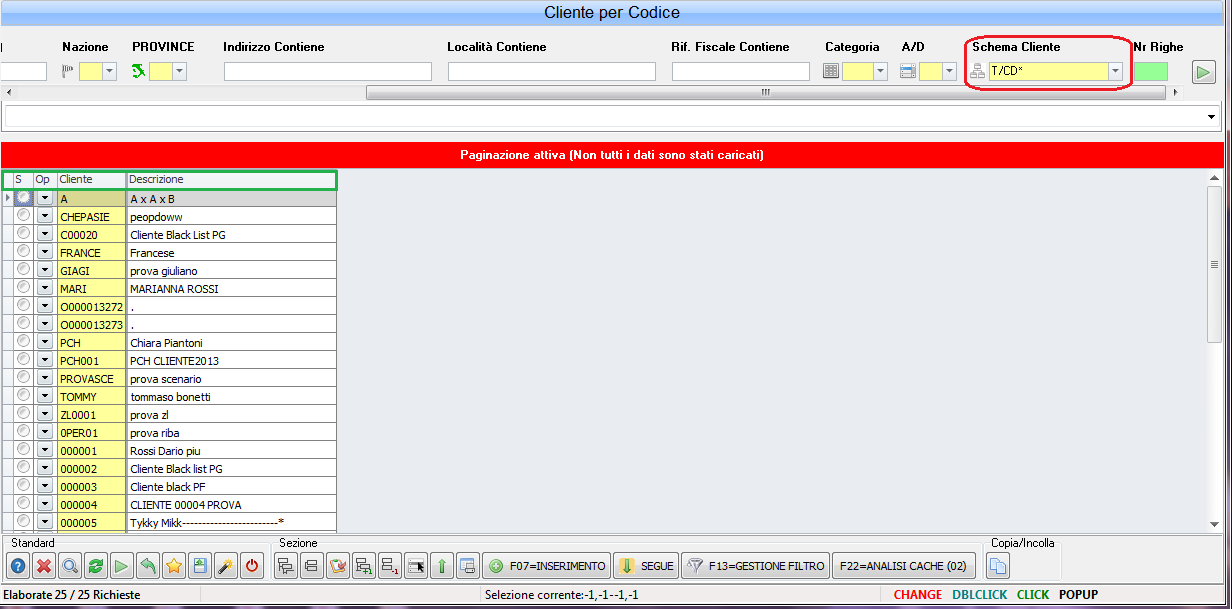
Con il termine schema si identifica l'insieme di colonne presentate nel risultato della query in scheda.
Tali colonne possono essere fissate dal pgm specifico di esecuzione della query, ma la maggior parte delle query prevede di appoggiarsi alla struttura di costruzione di schemi generica prevista dallo standard smeup (tramite la /COPY £IQ2). Quando si è in questa situazione nella richiesta parametri della query normalmente è prevista la possibilità di indicare un campo "schema".
 |
 |
E' importante notare, che lo schema rappresenta la base di definizione delle colonne, ma che non è l'unico strumento a disposizione per la costruzione dell'output finale. Allo schema si affiancano infatti gli strumenti di gestione del setup. L'insieme di tali strumenti costituisce una potente funzionalità grafica che permette in modo semplice ed accessibile anche all'utente di "personalizzare" la presentazione di un particolare schema.
In questo frangente è di particolare importanza l'eventuale riordinamento/raggruppamento dei dati, che va sottolineato, viene applicato esclusivamente ai dati caricati e non ha effetto sull'ordine di caricamento effettivo dei degli stessi. Quindi qualora il risultato della query preveda un numero di righe superiori a quello previsto dalla prima pagina, il riordinamento previsto dal setup viene semplicemente applicato ai dati caricati nella prima pagina secondo l'ordinamento previsto dalla query (es. se è previsto che gli articoli vengano caricati per codice, e poi tramite gli strumenti di setup li raggruppo per tipo articolo, tale raggruppamento viene applicato esclusivamente ai codici caricati sulla prima pagina. Se vedo quindi già più gruppi, finchè la paginazione dei dati non sarà completa, tale gruppi non potranno dirsi completi).
Per la configurazione della presentazione dei dati abbiamo quindi due livelli:
- Lo schema, che va predisposto dal sistemista, attraverso gli strumenti tecnici.
- Il setup di matrice, che permette di applicare al singolo schema un'ulteriore personalizzazione grafica da parte dell'utente.
Schema di default
Salvo che per la query specifica sia stato previsto uno schema, per tutte le query viene ripreso uno schema di default (per verificarlo basta guardare se è presente questa informazione nello scheda della query, cioè dell'oggetto Q1). Questo schema viene determinato secondo la seguente risalita:- Se presente, lo schema indicato nella scelta dello schema di default nelle finestra delle ricerche
- Se presente, lo schema avente codice Q/DFT_U
- Se presente, lo schema avente codice S/DFT
- Se presente, lo schema avente codice Q/DFT
- Se presente, lo schema avente codice T/DFT
- Se l'oggetto è una Tabella *TAB/*ALL
- Se l'oggetto è appartiene ad un file *FIL/*ALL
- Altrimenti è T/CD*
Aggiungere nuovi schemi
A standard vengono già previsti una serie di schemi per ogni classe oggetto smeup. Questo nel pensiero di limitare al minimo la necessità di introdurre nuovi schemi. Qualora sorga tale necessità è comunque possibile inserire nuove istanze di schemi.Di seguito viene riportata la documentazione di definizione degli schemi (oggetto Q2).
Cos'è un Q2
L'oggetto Q2 identifica l'elenco delle colonne di dati e la loro modalità di presentazione, all'interno di matrici di dati (nel senso matematico del termine) costituite da un elenco di righe facenti riferimento ad istanze della medesima classe (un elenco di articoli, di clienti, di movimenti di magazzino ecc.)
Il fatto di identificare tale insieme di colonne in un oggetto permette vari vantaggi:
- Dare la possibilità all'utente di scegliere quale schema utilizzare per un certa elaborazione di output .
- Dare la possibilità di sfruttare questa possibilità su elaborazioni completamente differenti che hanno in comune il fatto di elaborare istanze della medesima classe.
- Rendere disponibile, come per tutti gli altri oggetti di smeup, una serie di funzionalità di base, fra cui la funzione di gestione che permette di inserire/modificare/cancellare istanza della classe.
La codifica degli schemi
La gestione dell'oggetto Q2 si basa sulla struttura ramificata comune a tutti gli oggetti Qx. Per tale motivo esistono varie nature di schemi definite in modo eterogeneo (per fare un esempio confrontando la gestione dei Qx con le interfacce degli oggetti smeup, per queste, mentre posso avere attivi o gli articoli di smeup o gli articoli di un'altra applicazione, per gli oggetti Qx è come se avessi la possibilità di avere contemporaneamente sia gli articoli smeup che gli articoli di altre applicazioni nella medesima interfaccia. L'univocità del codice in tale struttura viene garantita dal fatto che ad ogni istanza, rispetto al suo codice originale, viene/vengono anteposti uno o due caratteri di prefisso, univoci per ogni fonte.
In smeup si possono trovare sia istanze di schema fornite dallo standard che istanze di schema creati appositamente nell'ambiente cliente. Di seguito ne vengono descritte le principali forme.
Gli schemi fissi distribuiti dallo standard
Ci sono vari schemi già predefiniti e distribuiti dallo standard. Questi, fra l'elenco delle istanze degli schemi selezionabili, questi possono essere riconosciuti dai prefissi "T/" e "Q/" (esclusi quelli che nel terzo carattere riportano una "X" es. Q/X01).
L'esistenza di due prefissi è dovuta alle due differenti modalità tecniche di implementazioni di tali strutture. Ognuna di esse presenta propri punti di forza/debolezza e quando si è in procinto di creare un nuovo schema, la scelta dell'ulta piuttosto dell'altra tecnica andrà effettuata sulla base di questi punti.
- Gli schemi "T/ - Da script SCN_NAV"
- Punti di forza
- La loro implementazione è particolarmente veloce: è sufficiente compilare le righe di uno script (con la possibilità di essere aiutati da un wizard) del file SCP_NAV
- Di per sè la definizione dello schema è inoltre molto semplice essendo di fatto nient'altro che un elenco di campi dell'archivio di appartenenza della classe o di attributi
- Permette di indicare l'utilizzo di colonne aggiuntive in maniera semplificata
- Il fatto che la sua definizione sia limitata o a campi dell'archivio o ad attributi, di fatto lo rende molto adatto a risolvere in modo ottimizzato estrazioni di dati tramite SQL.
- La loro implementazione è particolarmente veloce: è sufficiente compilare le righe di uno script (con la possibilità di essere aiutati da un wizard) del file SCP_NAV
- punti di debolezza
- le semplificazione e la strutturazione di questa forma di schemi costituisce anche il suo unico debolezza: non possono in fatti essere implementate eccezioni o deviazioni all'interno di tale struttura. Quando risultano necessarie queste funzionalità si possono utilizzare gli schemi "Q/"
- le semplificazione e la strutturazione di questa forma di schemi costituisce anche il suo unico debolezza: non possono in fatti essere implementate eccezioni o deviazioni all'interno di tale struttura. Quando risultano necessarie queste funzionalità si possono utilizzare gli schemi "Q/"
- Punti di forza
- Gli schemi da "Q/ - Da pgm B£IQ2_xx"
- Punti di forza
- Gli schemi Q/ nascono per sopperire alle debolezze degli schemi "T/": essi sono infatti costruiti da pgm RPGLE che può quindi applicare qualsiasi tipologia di logica di costruzione. Si pensi alla necessità di nascondere/visualizzare colonne in base a certe condizioni dell'ambiente (come i valori della tabella B£2) o alla necessità di calcolare informazioni che non possono essere reperite tramite l'utilizzo degli attributi. In questi pgm può essere inoltre interessante sfruttare la possibilità di passare un parametro "SchPar" (si veda la documentazione della /COPY £IQ2) attraverso il quale far recepire al pgm delle informazioni che permettono di fare assumere al pgm differenti comportamenti.
- Una particolarità di questi schemi è anche la possibilità di poter ritornare a fronte di una sola istanza più righe di matrice o al contrario (se può risultare opportuno) nessuna riga.
- Gli schemi Q/ nascono per sopperire alle debolezze degli schemi "T/": essi sono infatti costruiti da pgm RPGLE che può quindi applicare qualsiasi tipologia di logica di costruzione. Si pensi alla necessità di nascondere/visualizzare colonne in base a certe condizioni dell'ambiente (come i valori della tabella B£2) o alla necessità di calcolare informazioni che non possono essere reperite tramite l'utilizzo degli attributi. In questi pgm può essere inoltre interessante sfruttare la possibilità di passare un parametro "SchPar" (si veda la documentazione della /COPY £IQ2) attraverso il quale far recepire al pgm delle informazioni che permettono di fare assumere al pgm differenti comportamenti.
- Punti di debolezza
- Il principale punto di debolezza degli schemi Q/ può sussistere nelle performance: data la libertà di comportamento concessa a questa struttura, nell'utilizzare questa forma di schema, per ogni riga della matrice dovrà essere effettuata una chiamata alla £IQ2 passando in input l'istanza nel campo £IQ2ID e/o l'intera DS di riferimento nel campo £IQ2IN.
- Il principale punto di debolezza degli schemi Q/ può sussistere nelle performance: data la libertà di comportamento concessa a questa struttura, nell'utilizzare questa forma di schema, per ogni riga della matrice dovrà essere effettuata una chiamata alla £IQ2 passando in input l'istanza nel campo £IQ2ID e/o l'intera DS di riferimento nel campo £IQ2IN.
- Punti di forza
Creare nuovi schemi nell'ambiente cliente
A fianco degli schemi distribuiti dallo standard possono essere implementati degli schemi creati appositamente nell'ambiente cliente.
Mentre per gli schemi standard sussistono esclusivamente due forme di definizione degli schemi, per gli schemi dell'ambiente cliente esistono varie nature di definizione (tutte riconoscibili dai differenti prefissi). Va però notato, che la maggiore parte di queste nature esiste esclusivamente per recepire forme di definizione degli schemi sussistenti in passato, ma che oggi sono da considerarsi superate.
Fatta questa considerazione anche gli schemi creabili nell'ambiente cliente possiamo prendere in considerazioni esclusivamente due particolari nature: gli schemi "S/" e gli schemi "Q/X".
Questi due forme di definizione degli schemi presentano gli stessi vantaggi degli schemi standard T/ e Q/ con queste differenze:
- Gli schemi "S/ - Da Script SCP_QRY" invece che essere definiti nei file script SCP_NAV degli schemi T/ sono contenuti negli script SCP_QRY o SCP_QRYPER che dovranno essere definiti in una delle librerie di personalizzazione dell'ambiente cliente.
- Gli schemi "Q/X - Da exit B£IQ2_xx_U" invece si fondamento esattamente sulla stessa struttura degli schemi Q/ con la differenza di essere costruiti attraverso pgm di exit invece che dai pgm standard.
Gestire uno schema "S/ - Da script SCP_QRY"
Questi schemi vengono definiti all'interno di uno script nel file SCP_QRY (per lo standard), SCP_QRYPER (per le personalizzazioni).
Il nome dello script deve corrispondere al nome dell'oggetto della lista; nel caso in cui esista un membro il cui nome corrisponda a TipoParametroOggetto il sistema analizza quello in caso contrario cerca un membro con nome corrispondente al solo Tipo Oggetto. Ad esempio se si tratta di uno schema sui clienti verrà prima cercato il membro CNCLI e quindi il CN.
Quando si vuole quindi implementare un nuovo schema sarà innanzitutto necessario:
- Verificare se esiste già uno file sorgente SCP_QRY nella libreria di personalizzazione dell'ambiente.
- In caso contrario crearlo (copia ad esempio quello della DEV)
- In caso affermativo verificando la presenza del sorgente corrispondente alla classe interessata (facendo le dovute considerazioni sul tipo/parametro)
- Se opportuno prendere in considerazione la possibilità di sfruttare le istruzioni dello script INC.SCP per includere in differenti script le stesse istruzioni
- In caso contrario crearlo (copia ad esempio quello della DEV)
- SCH: definisce uno schema
- SCH.FLD: definisce una colonna dello schema
- G.SET.MAT: definisce il o i setup della matrice
Per il tag SCH.FLD ricopre un ruolo particolarmente importante il nome della colonna: indicando infatti in esso il nome di uno dei campi dell'archivio, o di un oav automaticamente verrà definito quale sarà il contenuto delle celle della colonna e come tale colonna va definita. L'intestazione, l'oggetto, la lunghezza, salvo vengano volutamente sovrascritte negli attributi del tag verranno automaticamente derivate dalla definizione del campo dell'archivio o dell'attributo.
Viceversa è possibile definire delle informazioni di differente natura, il cui codice può essere libero, ed i cui valori possono essere reperiti tramite l'applicazione di funzioni alle informazioni di base (costituite a loro volta dai campi del archivio di riferimento e dagli oav della classe). Sarà così possibile informazioni applicando formule quali decodifiche, attributi di attributi, formule SQL.
E' inoltre obbligatorio indicare sempre nello schema la colonna che identifichi l'istanza della classe di riferimento (es. per gli articoli il codice articolo). Tale identificazioni può avvenire alternativamente in questi modi:
- Attribuendo come nome di colonna il codice speciale "K01"
- Attribuendo alla colonna per l'attributo TYP il medesimo valore "K01"
SCH.FLD NAM(K01) FUN(CNC) PAR(R§NDOC,R§NRIG)
Per quel che riguarda l'utilizzo del G.SET.MAT, questo è opzionale ed in sua assenza verrà applicato come un default.
Quando invece sorge la necessità di aggiungere proprie specificità si ricordano queste considerazioni:
- L'utilizzo degli attributi di raggruppamento ed ordinamento, vanno utilizzati con particolare attenzione in quanto su matrici con paginazione potrebbero produrre risultati ingannevoli se anche il caricamento dei dati non avviene secondo il medesimo criterio indicato in questi attributi.
- Di sfruttare il più possibile l'attributo Parent, che permette di riprendere una serie di attributi, con la possibilità di specificare solo quelli specifici dello schema. L'elenco dei parent è contenuto nello script di scheda J3_SET_STD. In particolare si citano come valori di questo attributo i codici A01 (Matrice di default con raggruppamento) A08 (matrice di default senza raggruppamento e senza totali) ed A09 (matrice di default senza raggruppamento e senza totali).
- Va infine fatta questa considerazione in merito all'utilizzo delle funzioni: le funzioni di decodifica e di oav (qualora derivati), quando non sono applicate alle istanze della classe le decodifiche risultano maggiormente vantaggiose dal punto di vista delle performance, se applicate tramite la funzionalità di setup delle colonne aggiuntive della matrice (si veda l'attributo "Formulas" del tag G.SET.MAT).Questo perchè in estrema sintesi, mentre le colonne aggiuntive applicano le funzioni alla DISTINCT dei codici presenti nella matrice, le funzioni le applicano ad ogni singola riga.
Fa infine notato che dopo qualsiasi modifica allo script, per vederne l'effetto sarà necessario ricollegarsi o ricaricare l'ambiente.
Gestire uno schema "Q/ - Da pgm B£IQ2_xx"
Questi schemi, come detto sono definiti attraverso il programma B£IQ2_XX. Eventuali differenze a livello di parametro sono gestite all'interno del B£IQ2_XX. Unica eccezione sono gli schemi su oggetti ID, in questo caso il pgm richiamato è il B£IQ2_IDxx, dove xx corrisponde alle prime due lettere del file. Le differenze per i vari file che corrispondono a tali iniziali sono gestite all'interno del pgm.
Gli schemi Q/ che possono essere aggiunti nell'ambiente cliente, possono esserlo implementando programmi secondo la seguente codifica fissa:
- B£IQ2Ixx_U per gli oggetti ID (es. per IDCALANN0F creo B£IQ2ICA_U)
- B£IQ2_XX_U per tutti gli altri oggetti (es. per AR creo B£IQ2_AR_U)
- B£IQ2XXXXU per tutti gli oggetti ID non databases (es. per IDBRDISTDS creo B£IQ2DISTU)
Di seguito viene riportato il link al sorgente di esempio delle exit ed ad al pgm di gestione degli schemi standard dei calendari.
Vedi BASE Esempio (MBSMESRC-B£IQ2_XX_U)
Vedi BASE Schemi standard di loocup-CA Calendari (MBSMESRC-B£IQ2_IDCA)
Fra le istanze definibili a standard, di particolare rilievo è l'istanza avente codice Q/DFT. Se presente questo sarà lo schema utilizzato di default in tutte le query che non prevedono a loro volta uno schema di default specifico.
Va infine notato che dopo qualsiasi modifica ai pgm, per vederne l'effetto sarà necessario ricollegarsi o ricaricare l'ambiente.
Gestire uno schema "T/ - Da script SCP_NAV"
Questi schemi vengono definiti esclusivamente per lo standard all'interno di uno script nel file SCP_NAV. Il nome dello script deve corrispondere al nome dell'oggetto della lista; nel caso in cui esista un membro il cui nome corrisponda a TipoParametroOggetto il sistema analizza quello in caso contrario cerca un membro con nome corrispondente al solo Tipo Oggetto. Ad esempio se si tratta di uno schema sui clienti verrà prima cercato il membro CNCLI e quindi il CN. NOTA BENE: che esista o meno lo script di riferimento, per qualsiasi oggetto sussiste l'istanza _h_T/CD*_n_ che identifica lo schema minimale dato da codice e descrizione.
Quando esistono, sono inoltre di rilievo le istanze:
- T/DFT - Default, in assenza della compresenza di uno schema Q/DFT rappresenta lo schema di default di tutte le query che non prevedono a loro volta uno schema di default specifico.
- T/Q3 - Filtro, se indicato, identifica i campi che verranno presentati nella scheda di gestione del filtro di job
- SCH.SCH: definisce lo schema
- SCH.FLD: definisce una colonna
- G.SET.MAT: definisce il setup della matrice
All'interno dei comandi SCH.FLD è necessario indicare quale colonna visualizzare; è possibile indicare il nome di un campo del file master per l'oggetto dello schema oppure una colonna aggiuntiva. Ad esempio il comando SCH.FLD Name="L5CDOC_" presenterà la descrizione del campo L5CDOC mentre il comando SCH.FLD Name="L5SOGG_I_05_I_T$V§PA" visualizzerà la regione a cui appartiene la provincia dell'ente. Nel caso in cui venga specificata una colonna aggiuntiva non è necessario adeguare il setup, questo verrà adeguato automaticamente dal programma.
E' inoltre possibile impostare il parametro ESql con cui è possibile indicare un'operazione sql il cui risultato verrà riportato nella colonna.
Esempio: SCH.FLD Name="R5SAL" Txt="Saldo" ESql="R5IMPO-R5IMPA"
Il parametro Hdd="1" farà in modo che la colonna sia nascosta.
Omettendo l'attributo Txt verrà ripresa di default la descrizione del campo del file.
E' inoltre obbligatorio indicare sempre nello schema la colonna che identifichi l'istanza della classe di riferimento (es. per gli articoli il codice articolo). Tale identificazioni può avvenire alternativamente in questi modi:
- Attribuendo come nome di colonna il codice speciale "ID_LI"
- Attribuendo come nome di colonna il codice speciale "ID_OG"
Va infine rilevato che sono previsti inoltre i seguenti codici speciali di colonna:
- ID_DE, per gli oggetti che non appartengono ad archivi, identifica automaticamente la decodifica dell'oggetto (senza l'applicazione di colonne aggiuntive)
- ID_TP, identifica automaticamente una colonna nel cui contenuto verrà riportato fisso il codice della classe dell'oggetto.
Per quel che riguarda l'utilizzo del G.SET.MAT, questo è opzionale ed in sua assenza verrà applicato come un default.
Quando invece sorge la necessità di aggiungere proprie specificità si ricordano queste considerazioni:
- L'utilizzo degli attributi di raggruppamento ed ordinamento, vanno utilizzati con particolare attenzione in quanto su matrici con paginazione potrebbero produrre risultati ingannevoli se anche il caricamento dei dati non avviene secondo il medesimo criterio indicato in questi attributi.
- Di sfruttare il più possibile l'attributo Parent, che permette di riprendere una serie di attributi, con la possibilità di specificare solo quelli specifici. In particolare si citano come valori di questo attributo i codici A08 ed A09.
Va infine notato che dopo qualsiasi modifica allo script, per vederne l'effetto sarà necessario ricollegarsi o ricaricare l'ambiente.
Forme obsolete di definizione degli schemi
Come accennato al punto precedente oltre a quelle descritte in precedenza, esistono varie modalità di definizione degli schemi che esistono solo per recepire modalità di definizione presenti in passato, ma ad oggi considerate ormai superate (mancando di varie funzionalità sussistenti nelle nuove strutture). Appartengono a questa categoria:
- Gli schemi "I/": Vengono definiti tramite l'oggetto SP, che a sua volta è definito tramite la tabella INT. Avevano un forte utilizzo in 5250, mentre in loocup hanno lo svantaggio di non poter definire l'oggettizzazione delle colonne.
Forme deprecate di definizione degli schemi
Come accennato al punto precedente oltre a quelle descritte in precedenza, esistono varie modalità di definizione degli schemi che esistono solo per recepire modalità di definizione presenti in passato, ma ad oggi considerate deprecate. Appartengono a questa categoria:
- Gli schemi "P/": Questi schemi, vengono gestiti attraverso programmi aventi codice NomeFile_M dove Nome file indica il nome del file master dell'oggetto su cui la lista è definita senza il finale 0F. Questa forma è precedente all'implementazione degli schemi Q/ che di fatto ne hanno costituito una versione aggiornata.
Sospendere/Ripristinare istanze e/o fonti di schema
Vista la molteplicità delle forme di schemi possibilità è stata prevista la possibilità attraverso un exit fissa, avente codice B£IQ5G_U, di poter disattivamente gli schemi o direttamente le fonti stesse degli schemi, secondo una proprio logica personale. Attraverso tale funzionalità è inoltre possibile ripristinare anche quelle forme di schema sono state ritenute deprecate. Si veda il sorgente del pgm B£IQRB che contiene nelle schiere l'elenco di tutte le fonti disponibili, con l'indicazione anche della caratteristica di deprecabilità, nonchè il sorgente di esempio dell'exit B£IQ5G_U).
Vedi EQRY Funzioni sui Fonti Base delle (OJ*PGM-B£IQRB)
Vedi EQRY Interfaccia Fonte - Esempio Exit Controllo (MBSMESRC-B£IQ5G_U)
Modificare il setup dello schema
Per quel che riguarda le funzionalità di setup, si rimanda alla documentazione operativa della matrice. In essa vengono esposte tutte le funzionalità grafiche disponibili per l'utente. Documenti operativi
Matrice in generaleColonne matrice
Righe matrice
Celle matrice
Matrice raggruppamento
Bottoniera matrice
FAQ matrice
Copertina di una Matrice
Add new attachment
Only authorized users are allowed to upload new attachments.
G’day (anonymous guest)
My Prefs

JSPWiki v2.8.0